Обозначения¶
Week - количество недель за которые доступны данные
excess - превышение смертей относительно среднего числа смертей за 2015-2019 года, за доступное число недель
excess per population - превышение смертности, превышение числа смертей относительно численности населения, за доступное число недель
deaths avg per population - средняя смертность за 2015-2019 года, за доступное число недель
Для ориентирования:¶
Допустим, средняя продолжительность жизни составляет 100 лет.
И предположим, что в устойчивой популяции рождается столько же сколько умирает. Тогда смертность будет в среднем 1 из 100, умирает 10 человек на каждую 1000.
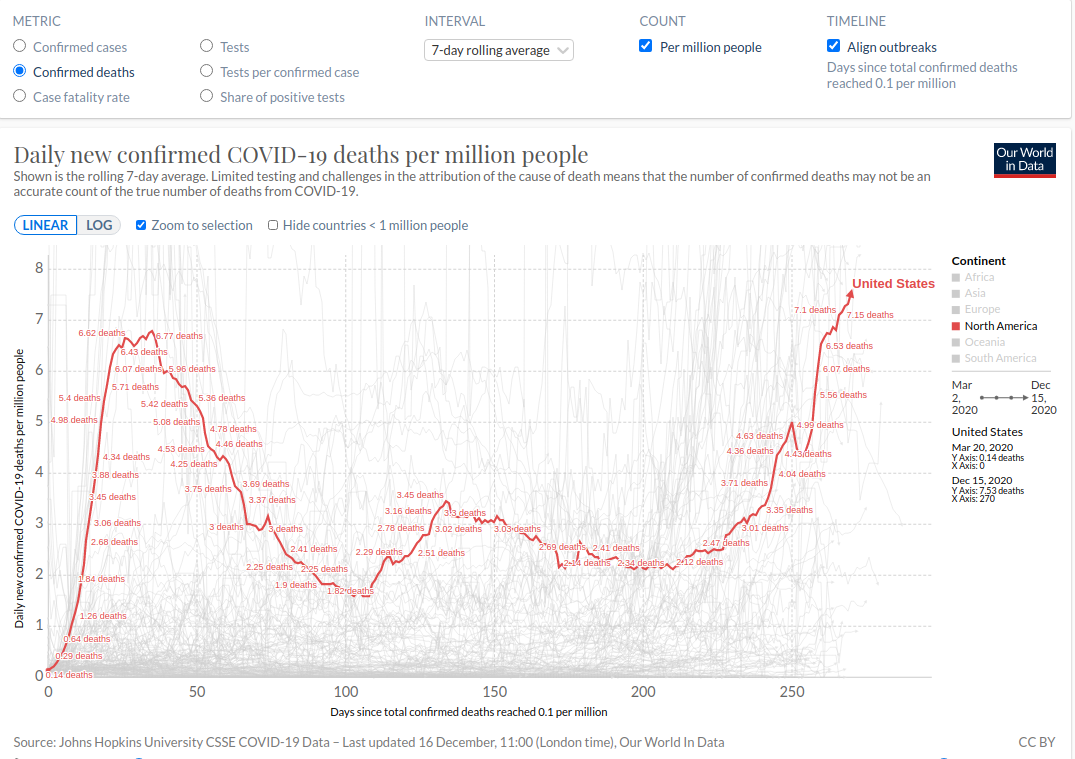
В Литве примерно 14 на тысячу, в США примерно 7 на тысячу. См. соотв. рис. выше.
Что означает, что превышение смертности в США равно 0.15 (относительно среднего числа смертей за 2015-2019 года)? Это значит, что вместо 10 человек в год на тысячу умерло на 15% больше. То есть 11,5.
И если судить субъективно только по своему окружению и по знакомым, то такое увеличение смертности практически незаметно.
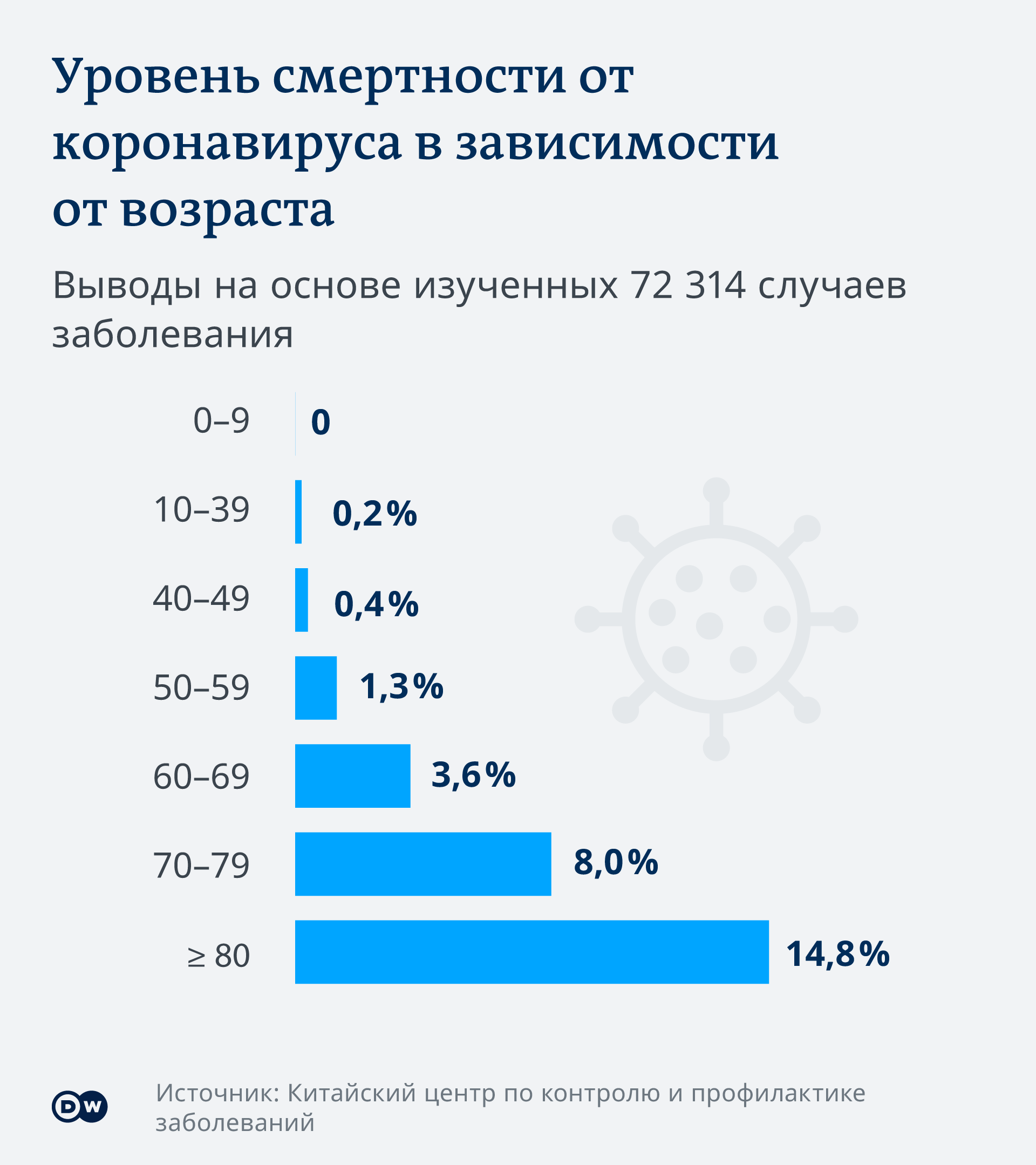
Особенно среди детей и молодых.
В соответствии с возрастным распределением летальности.
Например, среди московской епархии за 2020 год умерло почти в три раза больше чем в прошлом.
С другой стороны если в среднем за год умирало 2,5 миллиона человек, то увеличение смертности на 15% означает на 375 тысяч больше умерло. Не мало.
Так же нужно учитывать запаздывание данных о превышении смертности на несколько недель.
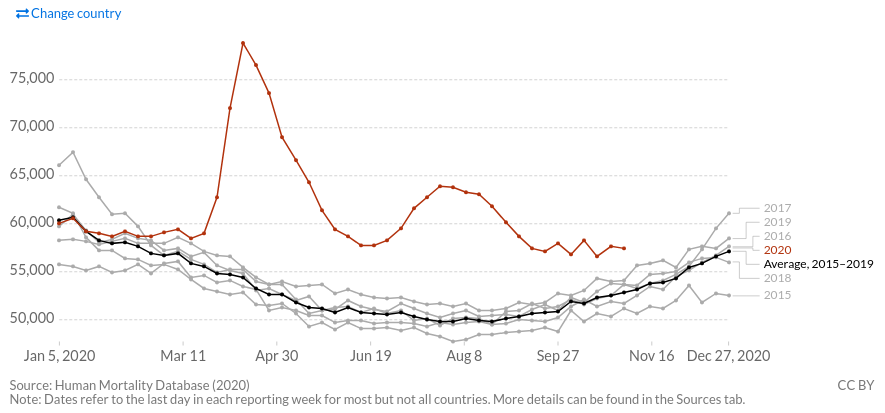
Ср рис 1 с рис 2
Средняя смертность за январь-октябрь 2020 складывается в основном за счет первой волны в марте-апреле, примерно два месяца. А так как ноябрь-декабрь-январь-февраль будет нелегким, то можно предположить (в зависимости от страны), что текущие оценки по превышению смертность к марту удвоятся или утроятся. За сезон 2020-03 - 2021-02.
Средняя смертность за январь-октябрь 2020 складывается в основном за счет первой волны в марте-апреле, примерно два месяца. А так как ноябрь-декабрь-январь-февраль будет нелегким, то можно предположить (в зависимости от страны), что текущие оценки по превышению смертность к марту удвоятся или утроятся. За сезон 2020-03 - 2021-02.
Как видно, данные о смертности можно использовать в двух вариантах:
"Ерунда, вместо 10 человек умерло всего лишь на 1,5 человека больше, обычный грипп"
В этом варианте не учитывается
- запаздывание данных о смертности
- перспектива второй волны
- в отсутствия принятых мер, смертность бы увеличилась в разы, с коллапсом медицины.
"Вау, умерло на 375 тысяч больше"
- но на фоне 2,5 миллионов умирающих ежегодно пока немного. Особенно среди окружения детей, подростков, молодых.
- Как это не цинично, но старики умершие в 2020 году, вряд ли умрут в 2021, 2022, 2023.
Третий вариант, переболеем все за 12 месяцев без вакцины. Если принять во внимание, что данные о летальности около 2-4%, а в Москве, например, 2,2% -4,4%. Предположим, что за 12 месяцев переболеют 50%, тогда к фоновому уровню смертности 1 из 100 добавится еще 1-2 из 100, и превышение смертности достигнет 100-200%, в среднем за эти 12 месяцев.
Существенная циркуляция в обществе первого варианта приводит большим рискам, что получится третий. Насколько потеряет экономика судить не берусь. А если понимать опасность и не пренебрегать ею, то возможно удастся не доводить до существенных потерь. А при быстрой ликвидации вспышки, и как следствие снятия мер, экономика начала бы уже восстанавливаться.










{kind=link}
{kind=link}
{kind=link}